|
|
假如您有一個應(yīng)用程序,隨著業(yè)務(wù)越來越有起色,系統(tǒng)所牽涉到的數(shù)據(jù)量也就越來越大,此時您要涉及到對系統(tǒng)進行伸縮(Scale)的問題了。一種典型的擴展方法叫做“向上伸縮(Scale Up)”,它的意思是通過使用更好的硬件來提高系統(tǒng)的性能參數(shù)。而另一種方法則叫做“向外伸縮(Scale Out)”,它是指通過增加額外的硬件(如服務(wù)器)來達到相同的效果。從“硬件成本”還是“系統(tǒng)極限”的角度來說,“向外伸縮”一般都會優(yōu)于“向上伸縮”,因此大部分上規(guī)模的系統(tǒng)都會在一定程度上考慮“向外”的方式。由于許多系統(tǒng)的瓶頸都處在數(shù)據(jù)存儲上,因此一種叫做“數(shù)據(jù)分片(Database Sharding)”的數(shù)據(jù)架構(gòu)方式應(yīng)運而生,本文便會討論這種數(shù)據(jù)架構(gòu)方式的一種比較典型的實現(xiàn)方式。
簡介
數(shù)據(jù)分片,自然便是將整體數(shù)據(jù)分?jǐn)傇诙鄠€存儲設(shè)備(下文統(tǒng)稱為“數(shù)據(jù)分區(qū)”或“分區(qū)”)上,這樣每個存儲設(shè)備的數(shù)據(jù)量相對就會小很多,以此滿足系統(tǒng)的性能需求。值得注意的是,系統(tǒng)分片的策略有很多,例如常見的有以下幾種:
- 根據(jù)ID特征:例如對記錄的ID取模,得到的結(jié)果是幾,那么這條記錄就放在編號為幾的數(shù)據(jù)分區(qū)上。
- 根據(jù)時間范圍:例如前100萬個用戶數(shù)據(jù)在第1個分區(qū)中,第二個100萬用戶數(shù)據(jù)放在第2個分區(qū)中。
- 基于檢索表:根據(jù)ID先去一個表內(nèi)找到它所在的分區(qū),然后再去目標(biāo)分區(qū)進行查找。
- ……
在這些數(shù)據(jù)分片策略之中沒有哪個有絕對的優(yōu)勢,選擇哪種策略完全是根據(jù)系統(tǒng)的業(yè)務(wù)或是數(shù)據(jù)特征來確定的。值得強調(diào)的是:數(shù)據(jù)分片不是銀彈,它對系統(tǒng)的性能和伸縮性(Scalability)帶來一定好處的同時,也會對系統(tǒng)開發(fā)帶來許多復(fù)雜度。例如,有兩條記錄分別處在不同的服務(wù)器上,那么如果有一個業(yè)務(wù)是為它們建立一個“關(guān)聯(lián)”,那么很可能表示“關(guān)聯(lián)”的記錄就必須在兩個分區(qū)內(nèi)各放一條。另外,如果您重視數(shù)據(jù)的完整性,那么跨數(shù)據(jù)分區(qū)的事務(wù)又立即變成了性能殺手。最后,如果有一些需要進行全局查找的業(yè)務(wù),光有數(shù)據(jù)分片策略也很難對系統(tǒng)性能帶來什么優(yōu)勢。
數(shù)據(jù)分片雖然重要,但在使用之前一定要三思而后行。一旦踏上這艘賊船,往往不成功便成仁,很難回頭。在我的經(jīng)驗里,一個濫用數(shù)據(jù)分片策略而事倍功半的項目給我留下了非常深刻的印象(當(dāng)然也有成功的啦),因此目前我對待數(shù)據(jù)分片策略變得愈發(fā)謹(jǐn)慎。
那么現(xiàn)在,我們便來討論一種比較常見的數(shù)據(jù)分片策略。
策略描述
這里我先描述一個極其簡單的業(yè)務(wù):
- 系統(tǒng)中有用戶,用戶可以發(fā)表文章,文章會有評論
- 可以根據(jù)用戶查找文章
- 可以根據(jù)文章查找評論
那么,如果我要對這樣一個系統(tǒng)進行數(shù)據(jù)分片又該怎么做呢?這里我們可以使用上面提到的第一種方式,即對記錄的ID取模,并根據(jù)結(jié)果選擇數(shù)據(jù)所在的分區(qū)。根據(jù)后兩條業(yè)務(wù)中描述的查詢要求,我們會為分區(qū)策略補充這樣的規(guī)則:
- 某個用戶的所有文章,與這個用戶處在同一數(shù)據(jù)分區(qū)內(nèi)。
- 某篇文章的所有評論,與這篇文章處在用一數(shù)據(jù)分區(qū)內(nèi)。
您可能會說,似乎只要保證“相同用戶文章在同一個數(shù)據(jù)分區(qū)內(nèi)”就行了,不是嗎?沒錯,不過我這里讓文章和用戶在同一個分區(qū)內(nèi),也是為了方便許多額外的操作(例如在關(guān)系數(shù)據(jù)庫中進行連接)。那么假設(shè)我們有4個數(shù)據(jù)分區(qū),那么它們內(nèi)部的條目可能便是:
| 分區(qū)0 | 分區(qū)1 |
|
|
| 分區(qū)2 | 分區(qū)3 |
|
|
在ID為0的分區(qū)中,所有對象的ID模4均為0,其他分區(qū)里的對象也有這樣的規(guī)律。那么好,在實際應(yīng)用中,如果我們需要查找“ID為2的用戶”,便去第2分區(qū)搜索便是;如果要查找“ID為8的文章的所有評論”那么也只要去第0分區(qū)進行一次查詢即可。既然查詢不成問題,那么我們該如何添加新記錄呢?其實這也不難,只要:
- 添加新用戶時,隨機選擇一個數(shù)據(jù)分區(qū)
- 添加新文章時,選擇文章作者所在分區(qū)(可根據(jù)Article的UserID求模得到)
- 添加新評論時,選擇文章所在分區(qū)(可根據(jù)Comment的ArticleID求模得到)
但是,我們又如何保證新紀(jì)錄的ID正好滿足我們的分區(qū)規(guī)律?例如我們向第3分區(qū)添加的新數(shù)據(jù),則它的ID必須是3、7、11等等。以前,我們可能會使用數(shù)據(jù)庫的自增列作為ID的值,但這似乎不能滿足我們“取模”的要求。以前我們可能還會使用GUID,但是我們?nèi)绾紊梢粋€“被4模于3”的GUID呢?其實我們還是可以使用自增ID來解決這個問題,只不過需要進行一些簡單的設(shè)置。例如在SQL Server中,默認(rèn)的自增ID屬性為IDENTITY(1, 1),表示ID從1開始,以1為間距自動增長。于是我們在創(chuàng)建數(shù)據(jù)分區(qū)的時候,每個自增列的屬性則可以設(shè)置為:
- 分區(qū)0:IDENTITY(4, 4)
- 分區(qū)1:IDENTITY(1, 4)
- 分區(qū)2:IDENTITY(2, 4)
- 分區(qū)3:IDENTITY(3, 4)
這樣,ID方面的問題便交由數(shù)據(jù)庫來關(guān)心吧,我們的使用方式和以前并沒有什么區(qū)別。
缺陷
那么這個數(shù)據(jù)分片策略有什么缺陷呢?當(dāng)然缺陷還是有很多啦,只是大多數(shù)問題可能還是要和業(yè)務(wù)放在一起考慮時才會凸顯出來。不過有一個問題倒和業(yè)務(wù)關(guān)系不大:如果數(shù)據(jù)繼續(xù)增長,單個數(shù)據(jù)分區(qū)的數(shù)據(jù)量也超標(biāo)了,怎么辦?
自然,繼續(xù)拆分咯。那么我們使用什么分區(qū)規(guī)則呢?和原先一致嗎?我們舉個例子便知。假設(shè)我們原有4個分區(qū),有一個ID為1的用戶落在第1分區(qū)里,他的文章也都在這個分區(qū)里,ID分別是1、5、9、13、17等等。于是在某一天,我們需要將分區(qū)數(shù)量提高到5個(財力有限,一臺一臺來吧),在重新計算每篇文章所在的分區(qū)之后,我們忽然發(fā)現(xiàn):
- ID為1的文章,模5余1,處在分區(qū)1。
- ID為5的文章,模5余0,處在分區(qū)0。
- ID為9的文章,模5余4,處在分區(qū)4。
- ID為13的文章,模5余3,處在分區(qū)3。
- ID為17的文章,模5余2,處在分區(qū)2。
呼,5個分區(qū)都齊了!這說明,如果我們保持記錄原來的ID不變,是沒有辦法直接使用之前的分區(qū)規(guī)則——無論您擴展成幾個分區(qū),(即便是從4個到8個)也只能“緩解”也不能“解決”這個情況。那么這時候該如何是好呢?例如,我們可以重新分配記錄,改變原有ID,只是這么做會產(chǎn)生一個問題,便是外部URL可能也會隨著ID一起改變,這樣對SEO的折損很大。為此,我們可以制作一個查詢表:例如在查詢小于1234567的ID時(這是“老系統(tǒng)”的最大ID),假設(shè)是100,則根據(jù)查詢表得知這條記錄的新ID為7654321,再以此去數(shù)據(jù)源進行查找。解決這類問題的方法還有幾種,但無論怎么做都會對新系統(tǒng)帶來額外的復(fù)雜度。而且,一次擴展也罷,如果以后還要有所擴展呢?
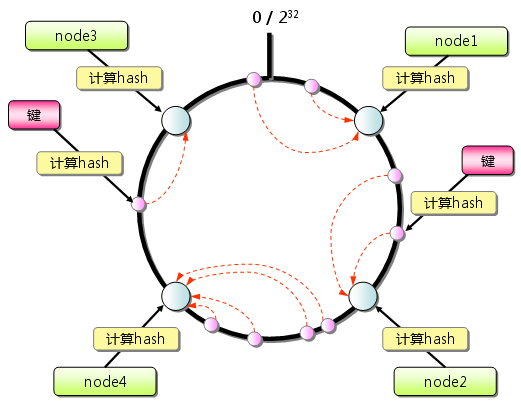
有朋友可能會說,取模自然會帶來這樣的問題,那么為什么不用一致性哈希(Consistent Hash)呢?現(xiàn)在一致性哈希是個很流行的東西,和Memcached一樣,如果不用上就會被一些高級架構(gòu)師所鄙視。不過在這里一致性哈希也不能解決問題。一致性哈希的目的,是希望“在增加服務(wù)器的時候降低數(shù)據(jù)移動規(guī)模,讓盡可能多的數(shù)據(jù)保留在原有的服務(wù)器”上。而我們現(xiàn)在的問題卻是“在增加服務(wù)器的時候,讓特征相同的數(shù)據(jù)同樣放在一起”。兩個目標(biāo)不同,這并不是一致性哈希的應(yīng)用場景。
我在以前的一個項目中曾經(jīng)用過這樣的方法:根據(jù)對訪問量與數(shù)據(jù)量的預(yù)估,我們認(rèn)為使用最多24個分區(qū)便一定可以滿足性能要求(為什么是24個?因為它能被許多數(shù)字整除)。于是,從項目第一次在生產(chǎn)環(huán)境中部署時便創(chuàng)建了24個數(shù)據(jù)分區(qū),只不過一開始只用了2臺服務(wù)器,每臺服務(wù)器放置12個數(shù)據(jù)分區(qū)。待以后需要擴展時,則將數(shù)據(jù)分區(qū)均勻地遷移到新的服務(wù)器上即可。我們團隊當(dāng)時便是用這種方法避免尷尬的數(shù)據(jù)分配問題。
沒錯,數(shù)據(jù)分區(qū)的數(shù)目是個限制,但您真認(rèn)為,24個數(shù)據(jù)分區(qū)還是無法滿足您的項目需求嗎?要知道,需要用上24個數(shù)據(jù)分區(qū)的項目,一般來說本身已經(jīng)有充分的時間和經(jīng)濟實力進行架構(gòu)上的重大調(diào)整(也該調(diào)整了,幾乎沒有什么架構(gòu)可以滿足各種數(shù)據(jù)規(guī)模的需求)。此外,無論是系統(tǒng)優(yōu)化還是數(shù)據(jù)分片都可以同時運用其他手段。
不過,我們目前還是想辦法解決這個問題吧。
策略改進
我們之所以會遇到上面這個問題,在于我們沒有選擇好合適的策略,這個策略把一些重要的“要求”給“具體化”了,導(dǎo)致“具體化”后的結(jié)果在外部條件改變的時候,卻無法重新滿足原有的“要求”。還是以前面的案例來說明問題,其實我們“要求”其實是:
- 某個用戶的所有文章,與這個用戶處在同一數(shù)據(jù)分區(qū)內(nèi)。
- 某篇文章的所有評論,與這篇文章處在用一數(shù)據(jù)分區(qū)內(nèi)。
而我們“具體化”以后的結(jié)果卻是:
- 某個用戶的所有文章ID,與這個用戶的ID模4后的余數(shù)相同。
- 某篇文章的所有評論ID,與這篇文章的ID模4后的余數(shù)相同。
之所以能如此“具體化”,這是因為有“4個分區(qū)”這樣的前提條件在,一旦這個前提條件發(fā)生了改變,則杯具無法避免。因此,我們在制定規(guī)則的時候,其實不應(yīng)該把前提條件給過分的“具體化”——具體化可以,但不能過度,得留有一定空間(這個稍后再談)。打個比方,還是前面的條件(XX和XX處在同一數(shù)據(jù)分區(qū)內(nèi)),但我們換一種具體化的方式:
- 某個用戶的所有文章ID的前綴,便是這個用戶的ID。例如,ID為1的用戶的所有文章,其ID便可能是1-A1、1-A2、1-A3……
- 某篇文章的所有評論ID,與這個文章的ID使用相同前綴。例如,ID為3-A1的文章的所有評論,其ID便可能是3-C1、3-C2、3-C3……
使用這個策略,我們便可以保證與某個用戶相關(guān)的“所有數(shù)據(jù)”都共享相同的“特征”(ID的前綴都相同),然后我們便可以根據(jù)這個特征來選擇分區(qū)——例如,還是以“取模”的方式。此時,我們已經(jīng)確保了“相同分區(qū)內(nèi)的所有數(shù)據(jù)都具備相同的特征”,即便分區(qū)數(shù)量有所調(diào)整,我們也只需要根據(jù)特征重新計算分區(qū)即可,影響不大。而以前為什么不行?因為“模4的余數(shù)”只是“結(jié)果”而不是“特征”,這里的“特征”應(yīng)該是“追本溯源后的用戶ID相同”,而這一點已經(jīng)體現(xiàn)在新的策略中了。
還是通過圖示來說明問題吧。假設(shè)原有4個分區(qū),使用“取模”的策略:
| 分區(qū)0 | 分區(qū)1 |
|
|
| 分區(qū)2 | 分區(qū)3 |
|
|
當(dāng)分區(qū)數(shù)量調(diào)整為5個之后(為了避免分區(qū)3空缺,我又補充了一些對象):
| 分區(qū)0 | 分區(qū)1 |
|
|
| 分區(qū)2 | 分區(qū)3 |
|
|
| 分區(qū)4 | |
|
是不是很合理?
值得一提的是,只要滿足了“特征”這個要求,其實選擇分區(qū)的方式并沒有什么限制。例如,我們可以不用“取模”的方式,而是使用“一致性哈希”——沒錯,這里就是一致性哈希的使用場景了。在利用“一致性哈希”來選擇分區(qū)之后,在添加服務(wù)器的情況下便可以相對減少數(shù)據(jù)的遷移數(shù)量了。
當(dāng)然,在實現(xiàn)時還可以運用一些技巧。例如,我們的特征并非一定要“把用戶ID作為前綴”——畢竟用戶ID可能比較長,作為ID前綴還真有些難看(請想象把GUID作為ID前綴,再加上另一個GUID作為ID主體的情景)。此時,我們可以把前提條件先進行一定程度的“具體化”(但就像之前提到的,不能過度),例如我們可以把用戶ID先進行取模,可能是1000萬,便可以得到一個落在較大區(qū)間范圍內(nèi)的數(shù)字。然后,再把這個數(shù)字作BASE64編碼,一下子前綴就縮小為4個字符以內(nèi)了。而且,1000萬這個區(qū)間范圍,無論是使用取模還是一致性哈希的方式來選擇分區(qū)都非常可行,一般不會造成什么問題。
總結(jié)
數(shù)據(jù)分片是系統(tǒng)優(yōu)化的常用設(shè)計方式之一。正如前文所說的那樣,數(shù)據(jù)分片的做法很多,本文提到的方式只是其中一種方式。這種根據(jù)ID特征的分片方式比較容易遇到的問題之一,便是在數(shù)據(jù)分區(qū)數(shù)量改變時造成的規(guī)則沖突,這也正是我這篇文章所討論的主要內(nèi)容。從這個角度看來,其他一些分片方式,如創(chuàng)建時間也好,查找表也罷,這樣的問題反而不太常見。如果您有這方面的經(jīng)驗或是疑惑,也歡迎與我進行交流。
現(xiàn)在Web 2.0網(wǎng)站越來越熱門了,此類項目的數(shù)據(jù)量也越來越大,從近幾年的討論形式可以看出,越來越多的人在強調(diào)什么大規(guī)模、高性能、或是海量數(shù)據(jù)。然后,似乎每個人都會橫向切分、縱向切分、緩存、分離。我猜,再接下來,估計又會有許多人以用關(guān)系型數(shù)據(jù)庫為恥了吧?但是,想想這樣的問題:博客園和JavaEye都是國內(nèi)技術(shù)社區(qū)的翹楚,它們都只用了1臺數(shù)據(jù)庫服務(wù)器。StackOverflow是世界上最大的編程網(wǎng)站(它是使用ASP.NET MVC寫的,兄弟們記住這個經(jīng)典案例吧),似乎也只用了1臺還是2臺數(shù)據(jù)庫服務(wù)器(可能配置比較高)及SQL Server。因此,即便是單臺服務(wù)器,即便是使用關(guān)系型數(shù)據(jù)庫,它在性能方面的潛力也是非常之高的。
因此,數(shù)據(jù)分片應(yīng)該只在需要的時候才做,因為它帶來的復(fù)雜度會比中心存儲的方式高出很多。這帶來的結(jié)果是,可能您的應(yīng)用程序還沒有用足架構(gòu)的能力就已經(jīng)失敗了,這樣各種投資也已經(jīng)浪費了。假如您一開始用最簡單的方式去做,可能很快會帶來成長所需要空間及資源,此時再做更多投資進行架構(gòu)優(yōu)化也不遲——架構(gòu)不是一蹴而就,而是演變得來的。當(dāng)然,第一次投入多少復(fù)雜度是個需要權(quán)衡的東西,這也是考驗架構(gòu)師能力的地方。架構(gòu)不是空中樓閣,而是各種真實資源調(diào)配的結(jié)果。
it知識庫:一種以ID特征為依據(jù)的數(shù)據(jù)分片(Sharding)策略,轉(zhuǎn)載需保留來源!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請第一時間聯(lián)系我們修改或刪除,多謝。