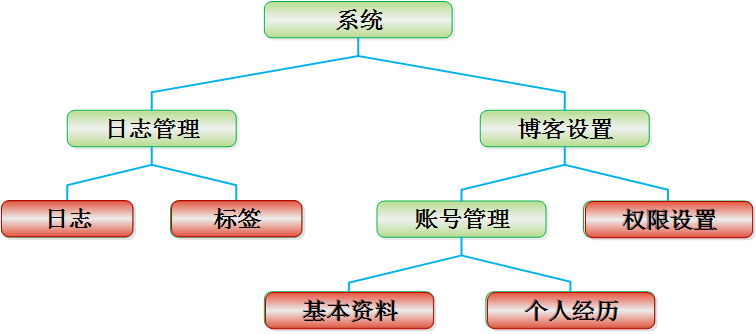
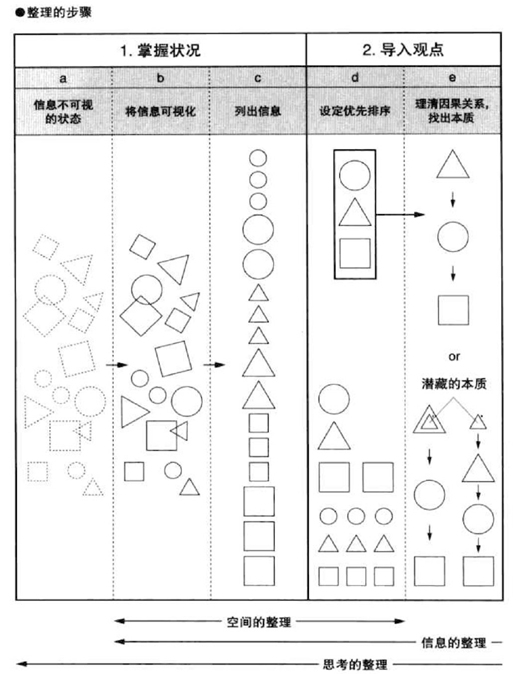
|
|
在NoSQL的許多產(chǎn)品中,我們通過(guò)benchmark可以看到的都是寫性能極度提升,而讀性能并沒(méi)有太大的漲幅甚至相對(duì)傳統(tǒng)RDBMS還有下降。比如Cassandra,MongoDB這兩個(gè)NoSQL的杰出代表。究其原因,我們可能會(huì)想到是因?yàn)楫?dāng)前UGC模式已經(jīng)發(fā)展到白熱化,用戶產(chǎn)生內(nèi)容導(dǎo)致讀寫比已經(jīng)接近或者說(shuō)小于1:1。
但是我認(rèn)為這絕不是個(gè)中真實(shí)原因。
1 緩存導(dǎo)致存儲(chǔ)的raw read效率不再重要
真實(shí)原因是我們對(duì)讀的優(yōu)化已經(jīng)做得足夠多了,數(shù)據(jù)存儲(chǔ)我們使用Memcached,TokyoTyrant/TokyoCabiNET等緩存存儲(chǔ),頁(yè)面及文件緩存我們使用squid,nginx proxy_cache等存儲(chǔ),都可以達(dá)到非常好的讀緩存效果,如果數(shù)據(jù)即時(shí)性要求不高,或者說(shuō)緩存設(shè)計(jì)合理(讀寫皆緩存),緩存命中率會(huì)足夠的高,因此我們無(wú)需再過(guò)分優(yōu)化底層存儲(chǔ)的raw read效率。
試想緩存層如果有高達(dá)99%以上的命中率,那么相對(duì)于raw read設(shè)備,我們的億級(jí)的數(shù)據(jù)讀取請(qǐng)求就輕松的變成百萬(wàn)級(jí)請(qǐng)求,上千并發(fā)輕松變成數(shù)十并發(fā)。當(dāng)然,這需要我們的緩存層足夠靠譜。比如nginx proxy_cache 可以多較多,這時(shí)候宕掉一臺(tái)不至于使全部讀請(qǐng)求穿透到底層存儲(chǔ)。至于多了之后purge等操作如何全面的執(zhí)行,不在本文討論之列。
綜上,raw read效率不需要再提升,因?yàn)槠湫枨笠呀?jīng)被緩存層大量取代。
2 無(wú)法取代的raw write功能
看到緩存減輕raw read的工作量,我們可以在想是否有方法可以減輕raw write的工作量。答案是不可以的。如果您認(rèn)為可以。可以留言探討。既然raw write的工作量是不可取代的,那么我們大概可以有兩種方法提升寫操作的性能。
3.1 sharding
通過(guò)對(duì)數(shù)據(jù)的分區(qū),我們可以將數(shù)據(jù)進(jìn)行分布式的存儲(chǔ),于是每個(gè)結(jié)點(diǎn)只會(huì)分配到一部分的raw write請(qǐng)求。這樣相當(dāng)于公司員工效率不變,多招了人。但由于結(jié)點(diǎn)的增多,其中有結(jié)點(diǎn)出問(wèn)題的效率也大大增加。于是我們不得不做一些replication操作來(lái)提供HA方案。
3.2 提升raw write效率
如上面的舉例,我們只能選擇提升raw write效率來(lái)實(shí)現(xiàn)總體(包括cache層)更好的讀寫效率。這里通常使用的方法就是將隨機(jī)的寫操作在內(nèi)存中進(jìn)行序列化,并在一定量后進(jìn)行順序的flush到磁盤操作。所謂將內(nèi)存當(dāng)成硬盤,將硬盤當(dāng)作磁帶就是這個(gè)意思。(可參見我更早的一篇文章:《NoSQL理論之-內(nèi)存是新的硬盤,硬盤是新的磁帶》)所以我們看到前面說(shuō)到的很多NoSQL產(chǎn)品著重對(duì)寫操作進(jìn)行了優(yōu)化,而對(duì)讀性能提升并不明顯,甚至不惜以更慢的讀作為提升寫操作性能的代價(jià)。
4 總結(jié)
由于讀性能可以通過(guò)設(shè)置合理的緩存策略來(lái)減少raw read操作的數(shù)量。因此不僅對(duì)讀寫比不大的情形需要著重進(jìn)行寫操作的優(yōu)化,對(duì)讀寫比大的情況下,仍舊需要優(yōu)化寫性能而非讀性能。
it知識(shí)庫(kù):關(guān)于NoSQL的思考-為什么我們要優(yōu)化存儲(chǔ)的寫性能?,轉(zhuǎn)載需保留來(lái)源!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請(qǐng)第一時(shí)間聯(lián)系我們修改或刪除,多謝。